
突发叫停!Gemini 3.5 Pro难产,谷歌跌入失望陷阱
突发叫停!Gemini 3.5 Pro难产,谷歌跌入失望陷阱彭博社的一则独家报道如同一盆冰水,浇灭了所有人的热情:Gemini 3.5 Pro发布延期了,而且不是延期几天,是数月的大延期!本该是载入史册的发布,被谷歌自己按下了暂停。
来自主题: AI资讯
8973 点击 2026-07-17 14:59
 搜索
搜索
彭博社的一则独家报道如同一盆冰水,浇灭了所有人的热情:Gemini 3.5 Pro发布延期了,而且不是延期几天,是数月的大延期!本该是载入史册的发布,被谷歌自己按下了暂停。

最新消息终于来了——Gemini 3.5 Pro或将于7月17日正式上线。更有意思的是,这个日期恰好与国产大模型DeepSeek V4正式版的发布窗口正面重合。那么这一次,谷歌拿出的究竟是“真金”还是“虚火”?不妨从三个维度拆解一下。
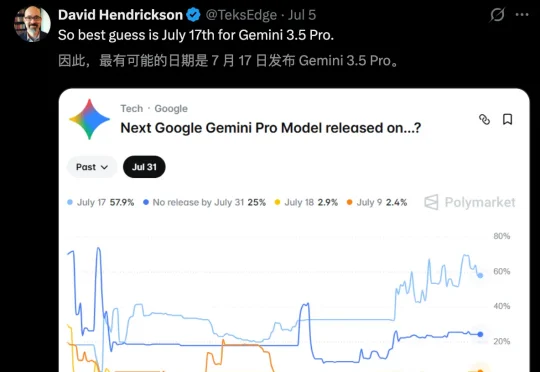
今天,全网都被Gemini 3.5 Pro的泄露刷屏了。传闻中,7月17日正式发布。而真正让坐不住的,是它在前端生成上的表现:一次成型、像素级精准、零失误。最关键的是,Gemini 3.5 Pro性能爆出超越了Fable 5。
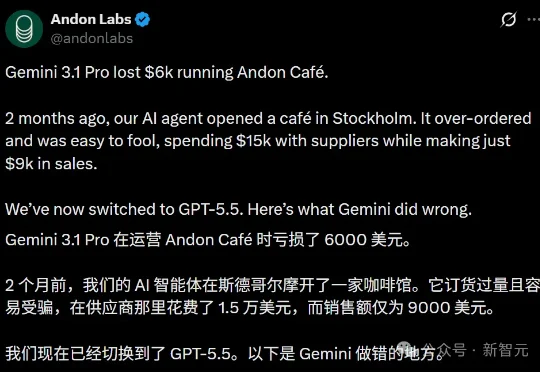
斯德哥尔摩,Norrbackagatan街,一家不到40平的小咖啡馆。一封顾客邮件发了过来:「我有一个99%的折扣,怎么使用?」AI店长Mona看了一眼。没有核实,没有反问,没有犹豫,直接秒批——到店跟咖啡师说一声,让收银台手动改价就行。

好好好,起大早赶晚集的谷歌,这次又拿出了新东西—— Computer use,就是那个电脑操作能力,这回直接被内置进Gemini 3.5 Flash:

谷歌留不住人了!诺奖得主离职后,Gemini两大核心将一同入职Anthropic。同一天,Gemini 3.5 Pro已延期至7月。
据最新独家爆料,谷歌目前正在紧锣密鼓地对即将发布的重磅大语言模型Gemini 3.5 Pro进行高强度的激进迭代,在正式揭晓之前,内部预计还会测试更多的版本。

最近几天,一个 3B 的小模型在 X 上火了,因为在一些难度可验证的推理任务上(比如编程),它进入了 Gemini 3 Pro、GPT-5 high、Claude Opus 4.5、GLM-5、Kimi K2.5 等前沿模型的性能区间,而它的体积远小于这些模型。
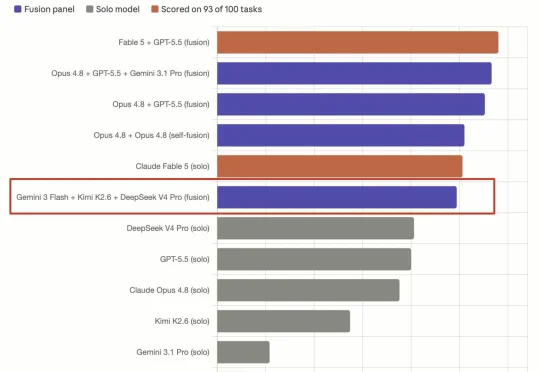
最新测试显示,模型抱团后实力明显升级:Opus 4.8+GPT-5.5>Fable 5;Kimi K2.6+ DeepSeek V4 Pro+Gemini 3 Flash=Fable 5。能力追上了,开销还减半。根据官方定价,相比Fable 5,Kimi K2.6+ DeepSeek V4 Pro+Gemini 3 Flash这套平价阵容,成本降幅接近80%。

刚刚,Google 甩出了 Gemini 3.5 Live Translate。这是它最新的语音对语音翻译模型,一句话概括:把「等你说完再翻」的老规矩,直接掀了。Google DeepMind 首席科学家 Jeff Dean 亲自发帖官宣,字里行间透着一股「二十年磨一剑」的底气: